Portfolio
GitHub
p2p-akka
A simple peer-to-peer system written using the Akka framework
Much simplified version of BitTorrent.
- A client loads a local file, converts it into a file hash, and an array of
“chunk hashes”, i.e. hashes of individual chunks of the file, and uploads
these hashes along with the file name to all “trackers” it knows.
- If the hash matches the hash of any file the tracker currently has by this name, or the tracker has no file with this name, the tracker adds this client to the list of known “seeders” of this file.
- A client requests the list of seeders of a file from a tracker, and receives their addresses
- The client initiates chunk requests from 4 seeders at a time, and they send the client their chunks. The client saves these chunks to a local file.
There are 4 different “actors”:
Tracker—– waits for people to say they’re seeding, or to ask who’s seedingClient- converts local files into hashes and sends them to Tracker
- responds to chunk requests from other clients
- Spawns a
FileDownloaderon download request
FileDownloader—– spawnsChunkDownloaders to download chunks- Tells
Clientactor when the download is finished - Spawns 4 concurrent
ChunkDownloaders - Blacklists peers and retries chunk-downloads when they fail
- Tells
ChunkDownloader—– requests a specific chunk of a file from a peer- Recieves the chunk in “pieces” (of the chunk)
- Upon receiving a complete “piece”, the
FileDownloaderis informed, so that it can update the current download speed, which is printed every second - If no piece arrives beyond a timeout (15 seconds), the download fails
- When the chunk transfer is complete, the
FileDownloaderis informed, os it can choose a new chunk to download, and a peer to download it from, and spawn a newChunkDownloader
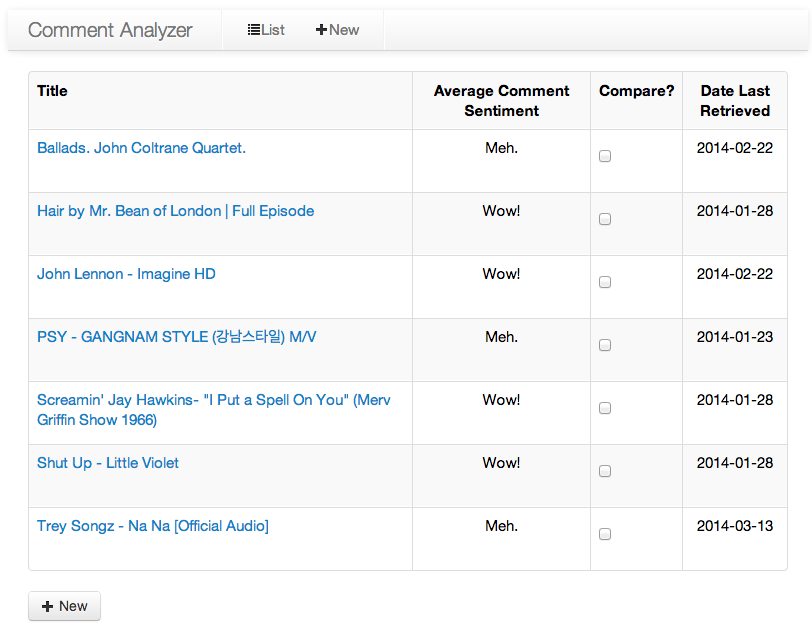
Comment Analyzer
The homepage has a listing of the average sentiments of the videos you’ve
previously found, as well as their average comment sentiment.
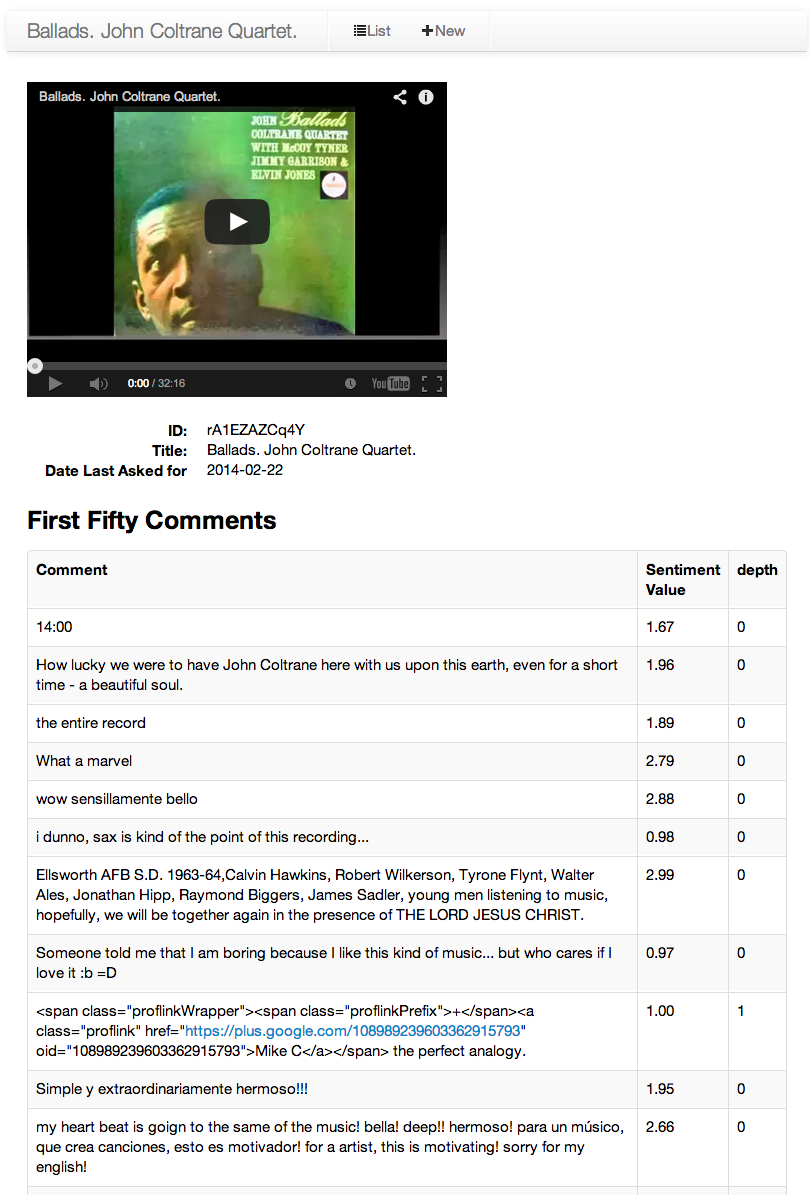
When you click on a video on the homescreen list, or after you search for a new video, you get to that video’s detail page.
Depth = 1 means that comment
was posted in reply to another comment. These comments are retrieved from a
completely different database (GooglePlus API) then the base level comments
(YouTube Data API v2), and responses to GooglePlus comments do not contain
which comment they are a response to in their metadata. So for now, I am
represent any level depth of commenting as level 1.
This sentiment analysis is performed by the Stanfords Recursive Deep Model for Semantic Compositionality, which boasts the ability to detect sarcasm etc. I think in the case of YouTube comments, something similar, like sets of known “Good” and “Bad” words would have worked better than this very sophisticated model because the comments don’t usually follow normal English tree forms.
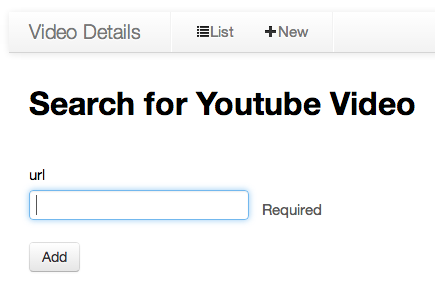
By clicking on the +New button, you are promped to enter the URL of the
YouTube video for which you would like to retrieve, analyze the comments of,
and add to the list on your homepage, e.g.
https://www.youtube.com/watch?v=fbAohexT0Ho.
Each stored video’s detail page, also has a -delete button at the bottom,
for removing it from your homepage.
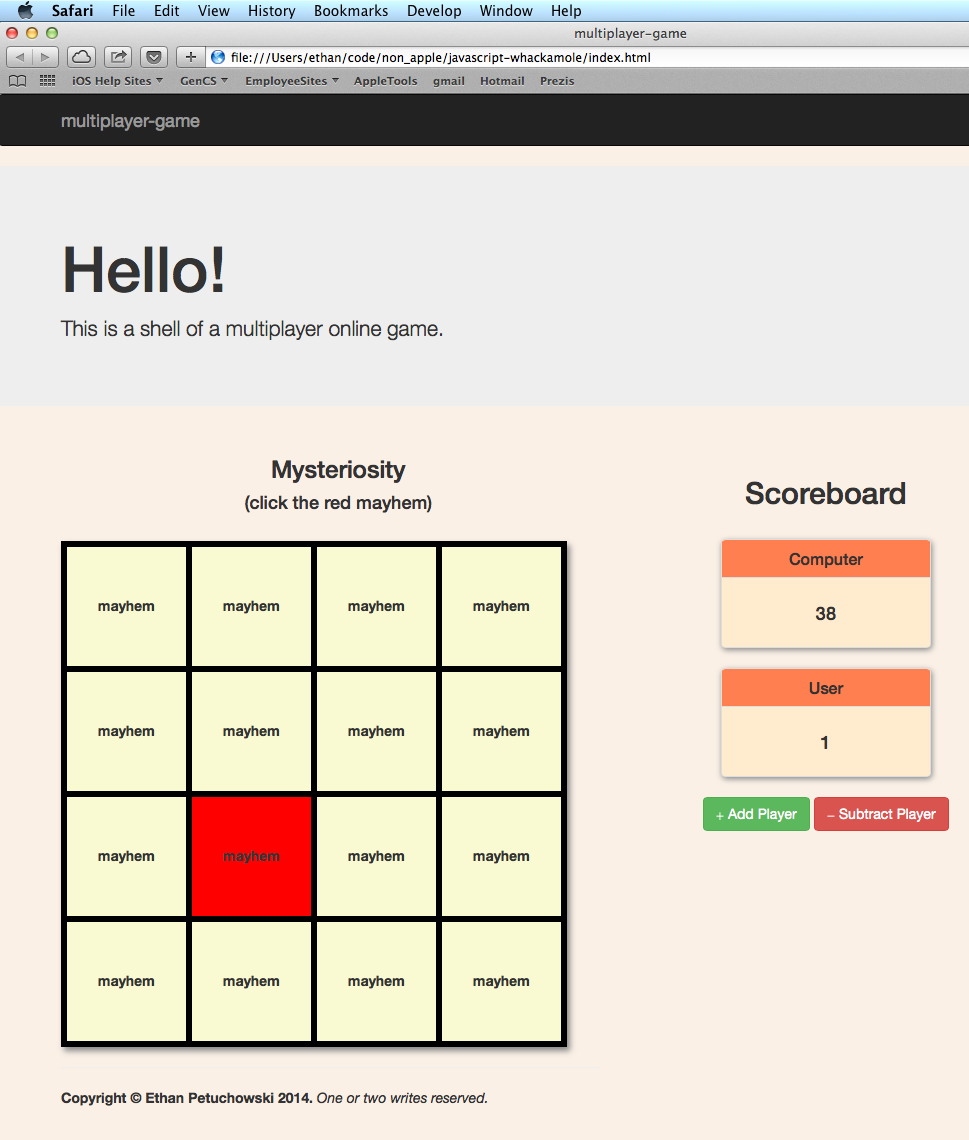
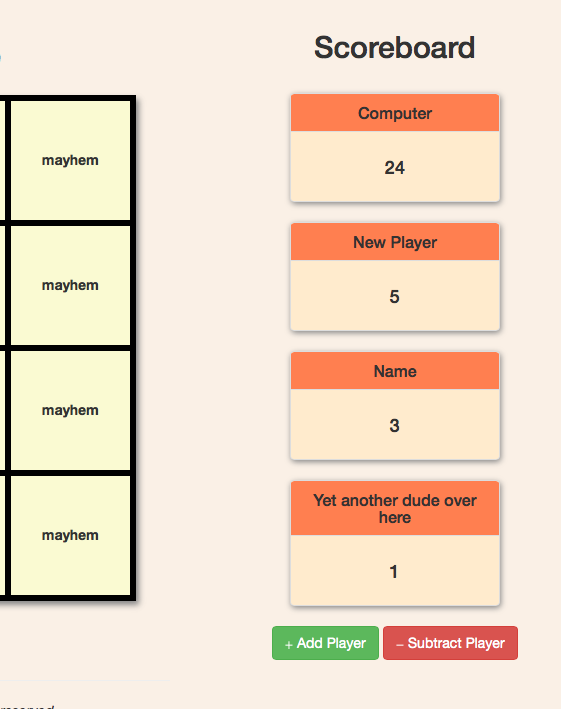
javascript-whackamole
It’s multiplayer-ready game, but currently only works for a single person against the computer. I made it to have a game to hook up to playframework and make it truly multiplayer via websocket. That’s still TODO though….
It uses Bootstrap because I don’t know any better and jQuery because it makes the code look cool.
Here are some screenshots of the game in action
Django-AudioFiles
First, use WebRTC to record audio from client’s microphone into a Javascript
Blob in the browser. Then upload the Blob to the server and store it as a
file with Django.
Pathfinder
This is a utility method for those times when you have a bunch of log files that you need to collect data out of, but they don’t always come in the same directory structure. Or there is a bunch of logged data files and you only want the ones with a particular filename prefix/suffix/type. This utility will allow you to easily and readably express the given directory structure and return to you a list of the absolute paths of only the files you want.
Given this directory structure
pwd -> upper_dir -> files a -> want it 1 --> dat data1.csv
\ \ \
\ \ > data I don't want.tsv
\ \
\ > don't want it
\
> files b -> want it 2 --> dat data2.csv
\ \
\ > data I don't want.tsv
\
> don't want it
Behold the following command
from pathfinder import pathfinder
my_files = pathfinder('.', ['upper_dir', '*', '^want', '.csv$='])
print my_files
=> ['/Absolute...Path/pwd/upper_dir/files 1/want it 1/dat data1.csv',
'/Absolute...Path/pwd/upper_dir/files b/want it 2/dat data2.csv']
Reference
Signature
def pathfinder(cd_able, path):
cd_able must be either a directory one may
cdinto from the current directory, or not a directory at all.path is the part that has the following DSL:
*means any file^...means “starts with”...$means “ends with”...=means “is not a directory”$must precede=if both are being used as directives- There is no escape if you want the directives as literals
Sure you could do something like
1
| |
but where’s the fun in that?